Thanks @bh, I got it why you chose the APL way.
I think I need to explain a little bit. So when I am doing the merge sort, I first made every element into a list of a single element, now, I group them by twos, 1st two, 2nd two, ..... now I merge them...
I will have about n/2 lists of 2 elements and possibly a list of one element (if n is odd), now I group them by two again, I will have n/4 lists of 4 elements and possibly a list of 3 elements... during the merge process, I need group them by twos...
The merge process requires me to group these list of sublists by 2s..., this process can be done functionally using reshape if reshape wasn't performed on the atom level - as APL did...
When I did the reshape (n/4)(2) on step 2 in the above process, for example, it's shorting the list to n/2... but if it were keeping the sublists as atom, it would be the correct size, because n/4 * 2 (size of sublists) * 2...
If we had implemented non-APL way (like my own reshape), if a user would like to use it - in APL way again, we can simply
first apply flattening on the source list, then feed into the reshape...
It's much clearer to use examples to illustrate.



You can see now the number of elements is about half of the original

My reshape don't work on the flattened list, rather treat each element (even if it's a list itself) as atom. 
Now, obviously, during the merge process, I would take each row (has two sublists), and merge them, and obtain a list of sublists, except this time the number of elements is doubled, with the exception of possibly one last sublist to have dimension one less. Now I can apply the recursion
The following is the implementation of merge sort inside out helper function...in there, inside fold, it's using my reshape, it's basically going through the reshaped list by rows, which is a pair of previously merged sublists, and merge them again... The idea is extremely simple. With the new notation, hopefully it's equally easy to understand.
I deviated slightly from the original reshape philosophy to help me with the merge sort process, if there is not enough elements, I don't recycle through the original list element, instead, I simply feed it an empty element - which is obtained by trying to get the element if the index is larger than the list.
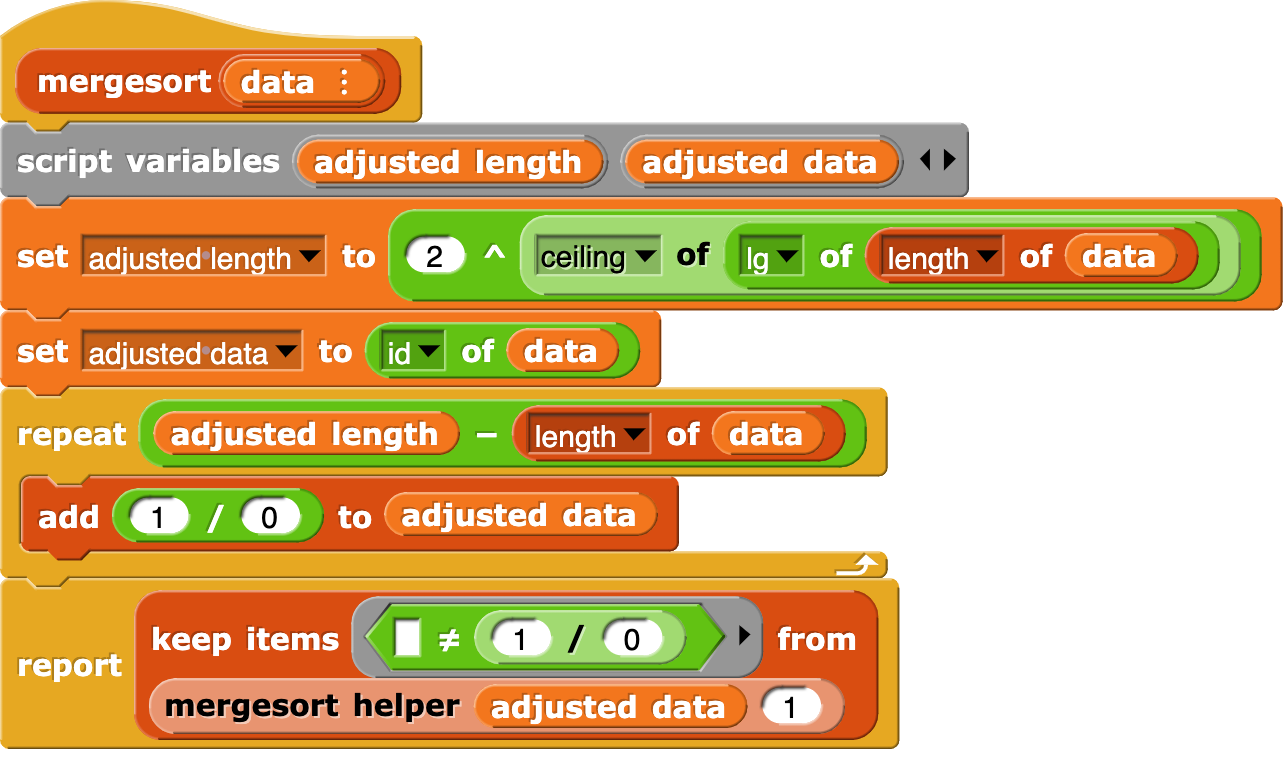
I studied Scala before, so I reworked some of the blocks to make them look more like Scala... But the script picture should include all the necessary bits and pieces. I also used my fold function, which is a slight generalization of combine block.
Sorry for the long illustration. Not even sure I did get my points crossed, there are times verbal communication would have been much easier... 
Thanks @bh one more time for your time and commitment to support the forum. You have always been patient and kind to everyone.