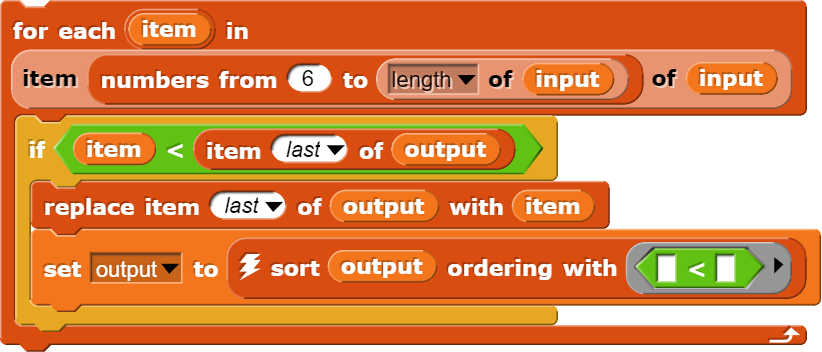
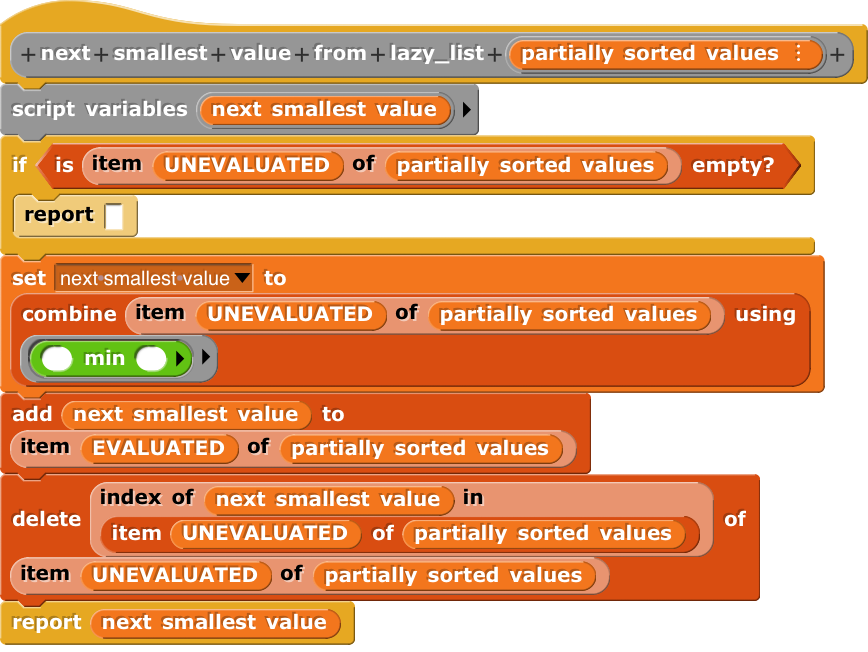
I would like to pick the first (n) sorted items from a large unsorted list (length: L), in a runtime-efficient manner.
What I found to work, but not very efficiently, is a combination of two blocks:
- from the List utilities library: sort (data) ordering with (function);
- from the APL library: take (howmany) from (array).
When combined, I call this algorithm A: - take (n) from [sort (data) ordering with (function)].
Thus the list is fully sorted first, and subsequently the first (n) elements are selected from the result of the first operation. Even though both functions were implemented quite efficiently, a full sort of a large list takes unnecessary runtime.
One alternative approach I found to work (algorithm B) is to using “combine” to select the key of the first item, subsequently picking and deleting this item from the list, and recursively picking (n-1) items from the remainder of the list. For very small (n) this turns out more efficiently than a full sort etc., especially if (function) evaluation is trivial (alternatively, (function) would be evaluated once for each element of the list, and retained for multiple usage).
However for somewhat larger (n), e.g. when selecting the first 100 items from a list of 1000, the inherent inefficiencies of this approach tend to dominate, making it even less efficient than a full sort (such as employed in algorithm A).
Can anyone suggest a potentially faster third algorithm for (n < L) ∧ ¬ (n << L) ?