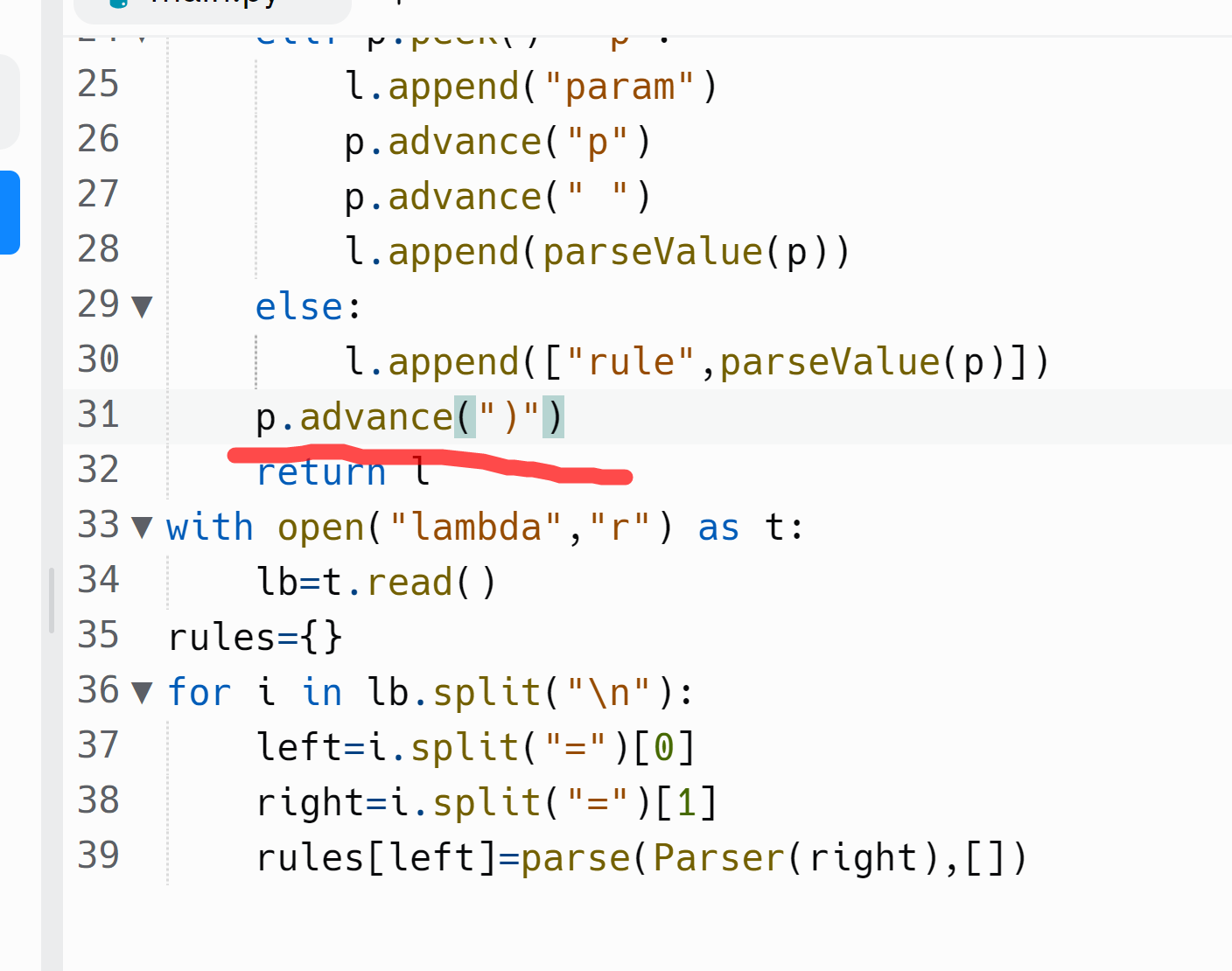
So im working with https://replit.com/@imcute-aaaa/lambda-parser#main.py
I made the tokenizing
Next I have to execute the tokens
but i dont know how to

When you see an open paren, you call the parser recursively and when you see a close paren the recursive call returns the parsed version of what was in the parens, which the outer parser treats like a single token. (The recursive parser will only see the matching close paren, because if there are any more paren pairs inside this one, there will be additional recursive calls to take care of them.)
I have to use before() to avoid problems like matching " " s
Oh god I don't want to read someone else's JS code. Yeah, tokenize the input and let their code handle quotes.
i mean matching "\x20"s
if i dont use before() my program would parse all the way down and ignore closing parens
also thats python cuz i dont like semicolons lol
Yeah I don't want to read someone else's Python code either...
Matching spaces? Spaces have matching?
You need to match a space so you can read the next parameter
I'm so confused. Give me an example.
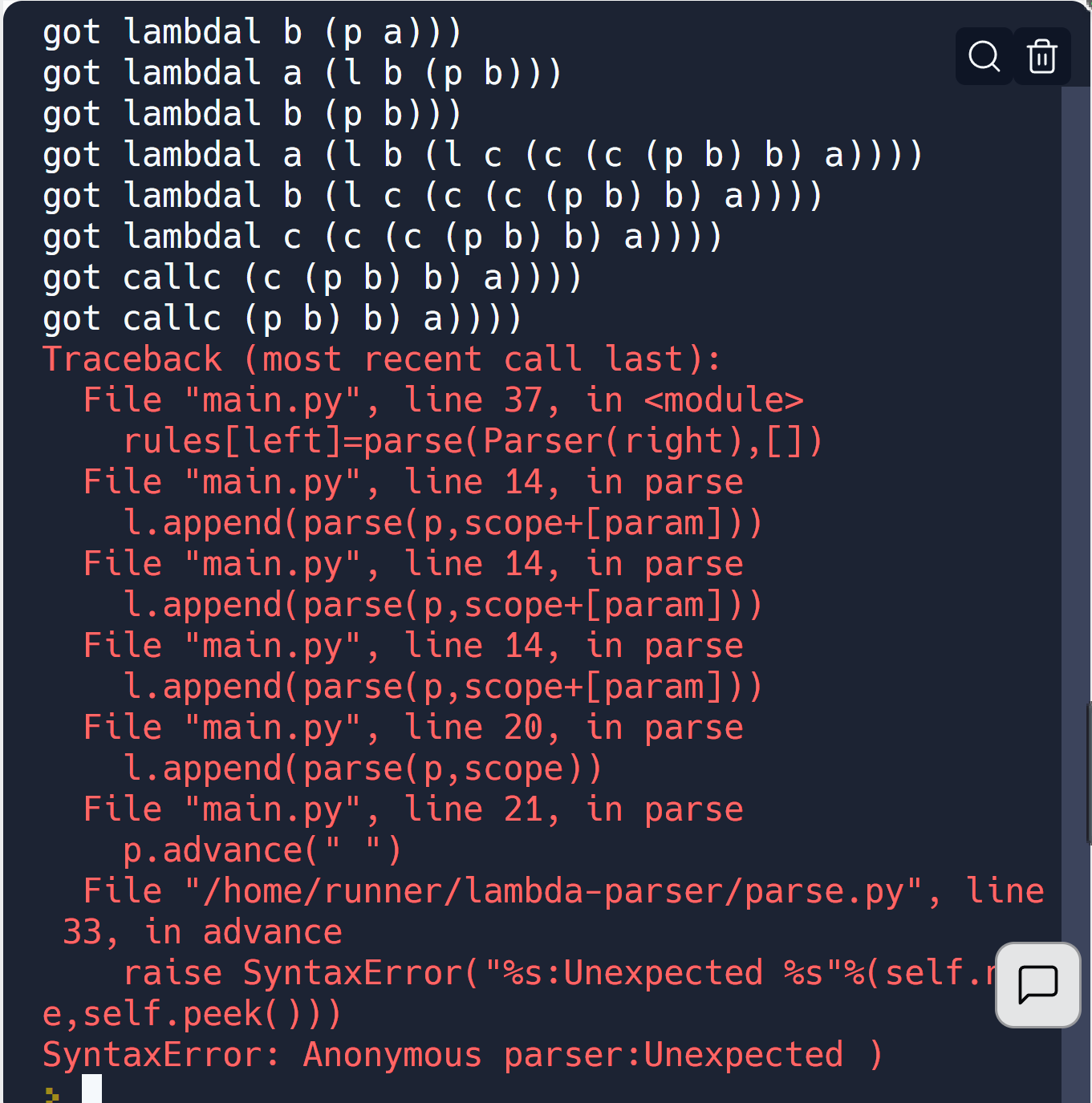
I don't get it. You're piling up all those close parens at the ends of lines, and it says there's an unexpected close paren, just as it should.
ahh
ah dumb me!forgot to comsume the close parens! ![]()
note its mid order DFS so you should have that stack of parens cuz they are right nodes
Groovy. Now I don't have to read your program. :~)