It’s actually a perfectly useful function, organizing (not sorting) data by key; and a serious implementation. As for me a more or less readable version is:
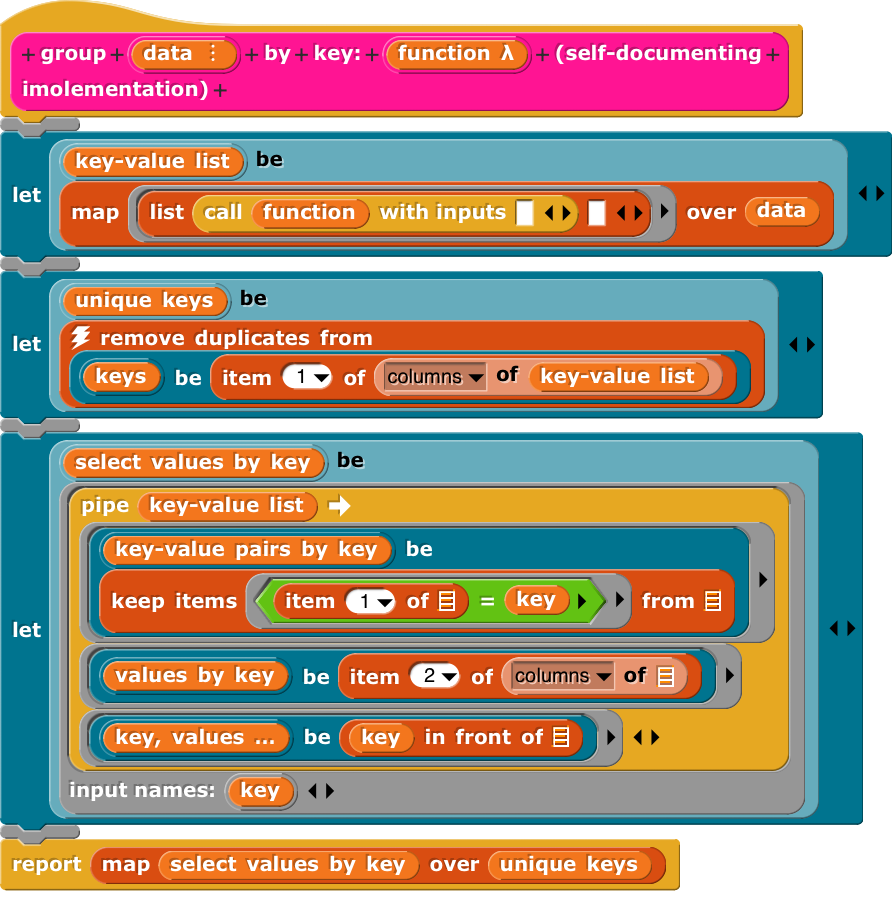
Update
I found ![]() (from the Frequency Distribution Analysis library) to do more or less the same thing, and - admittedly - both a little better, and faster.
(from the Frequency Distribution Analysis library) to do more or less the same thing, and - admittedly - both a little better, and faster.