I'm thinking of something like:

And about the specification:
- wildcards are: (),(?1), (?2), (?3) etc.
- any other items to be specified will be encountered while coding
Ah, okay. And instead of "hello *" you can just (JOIN hello (?1)).
Woah!
I actually encountered a functional issue: what does it mean to replace e.g. A by (1 2) in (A B) ?
Should the result be (1 2 B), or ((1 2) B) ?
I don't think there is a general answer to this question.
Even for replacing Snap ! code I haven't figured it out completely yet.
The way blocks are ordered in a decomposition is somewhat tricky.
That's why, in my current implementation:
... works, but:
... doesn't:
This isn't exactly the same question, but if you look up pseudoquote in the Scheme manual you'll see that there are two flavors of insertion: ,foo puts the entire foo into one item of the result list, but @,foo puts the items of foo (which must be a list) in the result ilst.
This is useful! Cool!
@anon45095554: would you share me the improved code with me?
Returning to @bh’s suggestion of PIPE being middle ground between composition and intermediate variables … in my view there are cases where consistent use of PIPE is impossible, or really complicated at least. An example:
I truly couldn’t say how to turn this into PIPE-based code.
If you drag the script pic to the script editor, the script should automatically be imported.
Oh, certainly. But there are lots of cases in which it isn't.
A tour de force! I'm very impressed.
But honestly, both versions are unreadable, imho. Fortunately, we now have a primitive (DISTRIBUTION OF, one of the options in the LENGTH OF block) to do this. :~)
My point is that you can't take a bizarre example that's unreadable no matter how you program it, and use it as an example of what's wrong with PIPE. PIPE does fine on reasonable algorithms. It's just like the Unix shell's pipe feature:
sort foo | grep bar | head
It doesn't' work for every case, but it works a lot of the time, and when it does work it's elegant.
(Btw, dardoro's pipe solution cheats a little, because the point of PIPE is to replace nested HOFs, and he still has some of those. :~) )
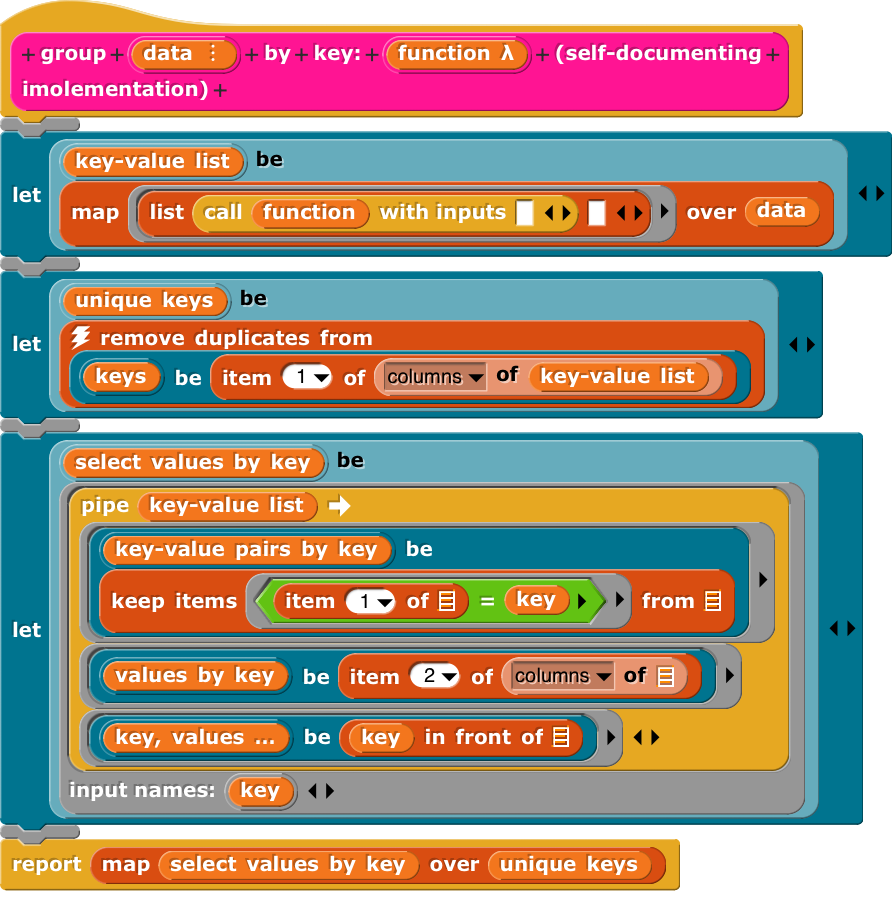
It’s actually a perfectly useful function, organizing (not sorting) data by key; and a serious implementation. As for me a more or less readable version is:
Update
I found ![]() (from the Frequency Distribution Analysis library) to do more or less the same thing, and - admittedly - both a little better, and faster.
(from the Frequency Distribution Analysis library) to do more or less the same thing, and - admittedly - both a little better, and faster.
I agree that your version is more readable! Although part of that is the long variable names, and those names could be used as the formal parameters of the functions in PIPE. But that tiny little gray spacer is very cute. :~)
Does (1) mean something other than (3)? If so, could you please expand on (1)?
Yeah, (2) is my fault; I'm going to try to get the manual up to date by Snap!Con.
I imagine (3) is Jens's effort to make the block super fast, but I'll enquire. I agree that testing with EQUAL might make more sense in this context of grouping, but EQUAL is way slower than IDENTICAL, not only for lists, but because of case insensitivity.
By the way, not sorting the keys makes the whole thing take 𝜽(n²) time, because you have to search the entire input for each key, whereas if you sort the keys you can do it in 𝜽(n log n) time.