I am not sure which category this should fall, so pardon me in advance if it's the wrong category.
In snap, there are so many amazing library functions one can find, so maybe what I am trying to discuss here may already have been covered and I had not had the opportunity to discover it.
So let's start with compose, in it's mathematical term is simply the composition of two functions: f and g
compose (f, g) (x) = f ( g(x) ) would take an input x, run through g and then to f to get the answer, and it has been provided by the compose block, which is extreme simple yet powerful.
But I found that I needed something a little extra, for example, the following scenario: I would like to have a function f which accepts two inputs, but g is a function which accepts one input, and the composition of f and g would accept two inputs, I would call such a composition a lift op. As follows:
lift (f, g) (x, y) = f(g(x), g(y))
The name lift (I originally called it my compose. ![]() ) is not originated by me, I searched on the internet, to see whether there is a pattern for this kind of things, of course, many many...
) is not originated by me, I searched on the internet, to see whether there is a pattern for this kind of things, of course, many many...
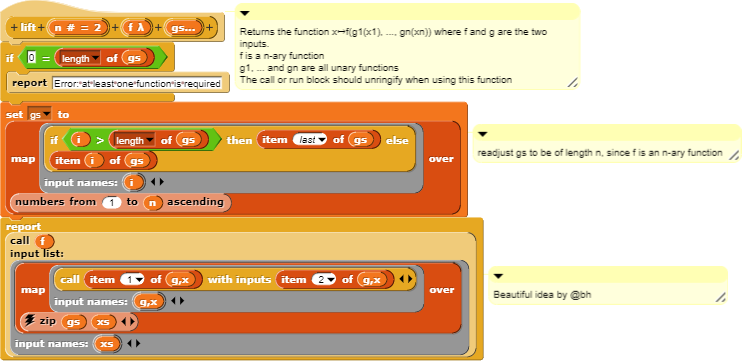
Or even in general, f is an n-ary function, and g1...gn are all unary function.
lift(f g1,..., gn) (x1, ..., xn) = f(g1(x1), ..., gn(xn))
So it's beneficial to implement such a block. I will share with you my implementation of lift2, and I tried to implement the general lift which would accept n, f, gs... as input, but I didn't go very far. I also will share with you a block to illustrate the application.
First, the lift2 implementation, which is extremely easy, thanks to the amazing power of snap.

(updated: Sept 30, fixed errors in the comment of the lift2 definition)
When only one g is selected, it will do: lift(f, g) (x, y) = f(g(x), g(y))
Now the application:

The above is simply saying: Merge sort a list of lists according the length of each sublists.
Welcome any comments and discussions.