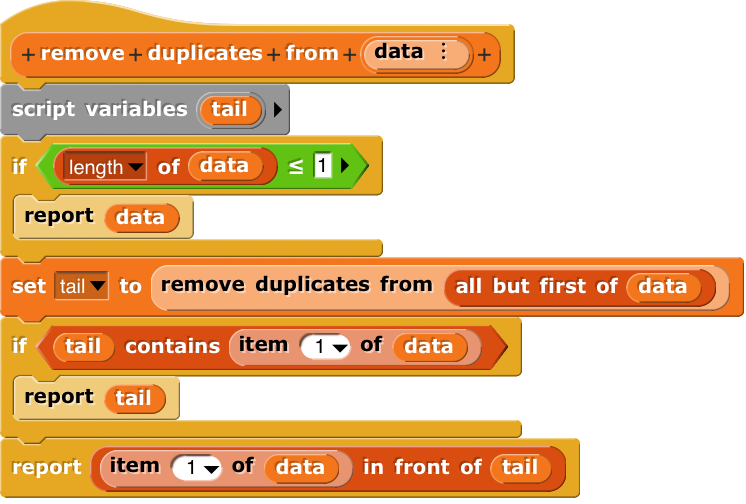
According to its online Help text, official List utilities library function REMOVE DUPLICATES “reports a new list whose items are the same as in the input list, except that if two or more equal items appear in the input list, only the last one is kept in the result”.
…
In reality however, the first one is kept:
…
Defendable though that approach may be, it’s not consistent with the approach taken by CONTAINS:
…
… Why is that significant?
Because any obvious implementation of REMOVE DUPLICATES in terms of Snap ! primitives would build on CONTAINS, e.g.:
…
…
I suspect the library originally contained an all-Snap ! implementation of REMOVE DUPLICATES that looked like this, BTW matching the Help text (see issue 1).
And so … ?
I suppose the current implementation of REMOVE DUPLICATES is very fast, so I’m not proposing to throw the baby out with the bathwater. There’s room for different implementations, just like Snap ! has two versions of “=“ (the other one named: IS IDENTICAL TO).
I propose two functions be added to the List utilities library:
A version of REMOVE DUPLICATES that compares sublists by content.
A version of CONTAINS that compares (sub-)lists by reference:
…
I agree about the help text, which (as you suppose) predates the primitive.
I think we need a more general solution to the =/IDENTICAL issue. One possible approach would be a Setting called "Compare with IDENTICAL." An overlapping candidate Setting, though, would be "Case sensitive comparisons." (It's overlapping because for text strings IDENTICAL means case sensitive comparison.) So maybe it'd have to be "Compare lists with IDENTICAL."
But maybe Settings aren't the best approach altogether. We'll have to talk about this. Stay tuned, but don't hold your breath.
A downside of using a (global) setting is that it affects all parallel threads (sprites, processes).
Another option is a switch in the function call, like:
Yeah that would be super flexible, but would also raise the bar to using those blocks. We certainly wouldn't use "≡" which doesn't mean anything to Snap! users; it'd have to be "identical," making the block even wider than your version. And it'd make debugging harder; you'd get an error message in a custom block because of the wrong choice of equality test in a sub-sub-subprocedure of the one where the error manifests itself.
I hear you about a global setting being too broad, but I think a per-block setting is too narrow, especially if there's an explicit Boolean to set it. Maybe something more like how compiled HOFs work, with an option in the context menu and then a symbol in the block. (In that context, where the setting is visible but not directly settable, a big bold ≡ might make sense.) (The forum isn't cooperating with my efforts to change the font of a character.)
I agree, that’s the downside of the switch-within-the-call option.
My guess is that most Snap ! users (high school students / college freshmen) expect REMOVE DUPLICATES to work like CONTAINS, i.e. comparing by content. So it would make sense to implement a suchlike version of REMOVE DUPLICATES as a primitive. And include any other versions in a library.
Does it remove any instance of the same thing appearing twice?
How does it order them?
Does it entirely remove any data value that is the same as another and not keep anything?
How does it work with tables?
What about case sensitivity
That’s why I think it should be called “condense multiple instances” or “condense duplicates”
And “remove duplicates” or “delete duplicates” should be for a block that cancels out list values entirely if they repeat Like if I have a list that’s 1,1,3,5,4,2,3 it would set the list to 5,4,2 because those are the only ones that don’t repeat
I also think an operation to test the total length of a list including it’s sub lists, as well as comparing 2 lists and seeing their differences would be very useful
The idea is that if you're removing duplicates from a list, the context is likely to be such that you don't care what order they end up in.
I'm sure you can come up with a counterexample, but most of the time it'll be that way. And by not promising anything we can change the implementation later. :~)
Removing all instances of items that appear more than once within a list to me seems a bit exotic, to be honest. When would anyone need such feature?
Whether capitals and non-capitals will be considered equal is already a setting within the Strings library; I agree it would be interesting to have it in place for regular comparisons as well.
By the same token one could want for lists to be compared as sets, i.e. irrespective of the order (and frequency) of their elements. The SciSnap! library does sets, but its treatment of sets is a bit handicapped by being an add-on (i.e. not integrated into the Snap ! core). I'm aware that introducing "set" as a regular data type is a non-trivial change. Even so ... apparently I'm not the only one who believes the order of elements within a list is often unimportant:
(this is exactly what distinguishes a set from a Snap ! list: in a set each element is unique, and the order of elements doesn't matter)
Testing the length of a list including all sub-lists is already really easy:
Comparing two lists and highlighting the differences, though interesting, may be very complicated - perhaps you could try to define what you’d want the result to look like, and build a prototype implementation?
It would report a list that has the same ammount of items as the largest list, and if a value is the same between them the value would be empty
If they are different then it would be the value in the second list input
The use case for a block that entirely removes all instances of values that repeat including the original could be
Using it with he previous block to detect what was deleted. So finding list duplicates.
The trouble with that approach is that there might be an actual empty item in one of the lists, so an empty item in the result is ambiguous. It'd be better to report a list of Booleans, True if the items agree, False if not. Even if there are Booleans in the input it wouldn't be ambiguous.