I recently used the dictionary feature and found the following:

It looks like the keys are not case sensitive.
Is this a bug or intentional?
Best regards
Karl
in Snap!, text comparisons aren't case sensitive, so it would make sense that keys aren't case sensitive either.
they arent however when using unicode blocks they are
Case sensitivity is just a really terrible idea in pretty much every context. Just because Kernighan and Ritchie made that mistake in, what, 1980?, every programming language since has slavishly followed it.
That's a little different. 'A' and 'a' have separate Unicode codes; if we say we're providing Unicode values, we have to follow Unicode! Similarly, there are Unicode codes for 𝑖𝑡𝑎𝑙𝑖𝑐, 𝐛𝐨𝐥𝐝𝐟𝐚𝐜𝐞, 𝓈𝒸𝓇𝒾𝓅𝓉, 𝔉𝔯𝔞𝔠𝔱𝔲𝔯, etc., styles. But different styles for the same letter should all compare equal (although I bet they don't...).
The IS IDENTICAL TO block does case-sensitive comparison when applied to texts.
I - strongly - disagree on this one. IMO case insensitivity is a questionable idea of the LOGO pedagogy that we've been slavishly chugging along, and it feels much like being forced to drive on the wrong side of the road just because a handful of American-English based project ideas in the mid-20th century had funny ideas about what typography consists of on underwhelming computer screens. There are only a very few select situations in which case insensitivity comes in handy, and those could very easily be accomplished the way every other programming language deals with them: By converting two strings to a common case before comparing them for equality.
German words often have distinctly different meaning depending on whether they are upper cased or lower cased. Here are a 2 examples off my head:
Ungeheuer - monster
ungeheuer - very
Dichter - poet
dichter - tighter
Not being able to create a dictionary with unique entries for these words with very different meanings is a serious impediment to dealing with language.
But it's not just about dictionaries. In German the very same word with the very same meaning can sometimes refer to something entirely different if capitalized depending on the context it is used in. Example:
Der Gefangene floh - the prisoner fled
Der gefangene Floh - the captured flea
Claiming that those sentences are "equal" and that casing is "just typography" and "a bad idea" is culturally biased, to put it mildly.
yes especially when dealing with security Imagine your password is ThIsIsNtAgOoDpAsSwOrD
and some one got in with thisisntagoodpassword
Jeez, doesn't German capitalize the first word of a sentence?
Maybe I'm overstating my case, sorry about that. But I stand by my claim about what the default behavior of computers should be.
I'm thinking about your claim that case insensitivity comes from Logo. That's certainly technically wrong; Logo got it from Lisp. If anything, what we relevantly got from Logo is undoing the distinction between symbols (names of things, basically) and strings (natural language text). And the pedagogic argument for that simplification is obvious.
I'll grant you that there are arguments for case-sensitive strings, but I'm adamant that symbols should be case-insensitive, so Foo and FOO should be the same variable. Letting them be different just asks for bugs.
As for strings, what does the search command do in text editors (or browsers, or anything with a search command) in German text? I claim that even in German, false positives aren't as bad as false negatives. And we have IS IDENTICAL TO for cases where you need case sensitivity.
The original topic of this thread was whether we should change the blocks that use comparison indirectly, such as CONTAINS, to let the user specify whether comparison should be case sensitive, and if so, what the notation should be. But, in terms of the history and best practice for CONTAINS, I claim this is another case in which false positives are better than false negatives, if we have to choose a default behavior.
So I think that Logo's comparison behavior didn't spring full-grown from Wally's head, but is consistent with the general history of string comparison in computer software.
Yes, passwords are a special case in which comparison should be case-sensitive. But, first of all, login dialogs give "passwords are case-sensitive" hints; they don't give "usernames are case-insensitive" hints. That's because users expect case-insensitivity as the default. And second, as xkcd points out, given the speed of modern computers, it's a mistake to rely on case-sensitivity in crafting passwords (versus relying on long passwords).
honestly its not hard to just add unicode blocks to your code so I agree that it should behave like this as its easy to add case sensitivity to your projects and it helps when case sensitivity doesn't matter such as usernames if the default is case sensitivity it would require a lot more code to turn it of than it does to turn on. It took a while to rewrite it because I was having fun with Grammarly's ai
(it wrote a taylor swift song)
Though I’m not convinced by the German language argument per se (either way, natural languages are notoriously ambiguous, as homonyms are ubiquitous), I tend to agree with @jens’s position in favor of case-sensitive comparisons as the standard procedure. Ignoring capitalization implies loss of information; transformations are strictly a one-way process.
Nevertheless, case-insensitive comparison is often useful. An as yet unresolved question is how to facilitate this. In recent forum topics on this and similar subjects, several mechanisms have been proposed:
- Convert individual items before including them into a data structure;
- Employ separate functions (in this case: for case-sensitive vs. case-insensitive operations);
- Set a switch within function calls, specifying which algorithm will be executed;
- A (global) setting specifying the same for all relevant functions in all parallel processes.
`
… To this set I would like to add a 5th option, perhaps a happy middle ground: - A function to pre-process all items within a data structure, regardless of nesting level, like:
`
Implementation:

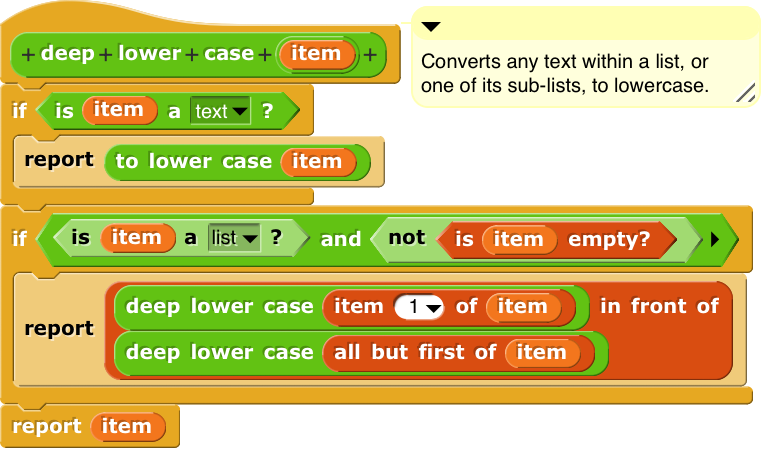
That would work technically, but for a young novice it'd be a significant barrier to entry to (I claim) the expected default behavior. If Jens reports that ⌘F in TextEdit on a German Mac defaults to case-sensitive search, I'd be open to change my idea about "the expected default behavior."
But regardless of how default search works, the whole idea of deep-mapping a function over a tree structure is a difficult idea. My SICP students at Berkeley often had trouble with tree recursion, especially with the car/cdr implementation of deep mapping in your block code. I think you're thinking too much about what can be implemented, and not enough about what a kid can learn. If my 18-year-olds at Berkeley had trouble with it, our 12-year-olds will a fortiori.
Do you mean undergraduate students don’t grasp the concept of deep mapping at all (as a user), or that they have difficulty in understanding how to build code to implement it (as a developer)?
As for 12-year olds: they’re used to assembling their classroom presentations from pieces of information collected on the internet, so I guess they won’t have any objection to using a function from a library (as-is).
How to build code, or even how to read code that uses branched recursion. They try to step through it mentally and get hopelessly lost, especially the ones who think all the recursive calls share one instance of the local variables. I try to convince them not to step into the recursive calls but just to take on faith that they give the right answer, and just work out how that lets this call give the right answer. Eventually most of them believe me, but even at the end of the course, too many students still don't really believe in recursion, as demonstrated by their work on the final exam.
That may satisfy the kid (although you'd be surprised how many want to understand the innards of the library code), but it doesn't satisfy me as a teacher. Recursion is too beautiful for them not to bask in understanding it!
My nominee for the most beautiful piece of code in the world:

I love how it combines recursion and HOFs to achieve its goal. I want our 12-year-olds (or 16-year-olds taking BJC!) to appreciate its beauty.
Ah, yes, your general version of deep map is very nice indeed. I wasn’t aware of it being available from an official library (I wonder why it’s in the APL library instead of the more obvious List utilities).
So preprocessing a data structure for case-insensitive comparison is simply:
![]() .
.
Should be there too, I guess. It's in APL so that you can load APL without loading any other libraries and it has everything it needs.
Is deep map an APL primitive?
What I know is the block is called by no other block from the APL library:

Oh that's interesting. It must be left over from an earlier stage of developing the library (which I did in a big rush, against a deadline (so that it could be released at the same time as hyperblocks in Snap! itself)).