I have already sorted the table on 1st column, using this block:

But now I need to sort it additionally on the 2nd one (because there are many equal values in the 1st column):

Any ideas? How to do it?
I have already sorted the table on 1st column, using this block:
But now I need to sort it additionally on the 2nd one (because there are many equal values in the 1st column):
Any ideas? How to do it?
The textbook answer is that first you sort on the second column, then on the first, using a "stable" sort algorithm -- one that leaves equal values in their original order. Alas, mergesort is very not stable.
What I would do is invent a predicate %A SORTS BEFORE %B ? that says if col 1 of A < col 1 of B then True; if col 1 of A < col 1 of B then False; otherwise (so they're equal in col 1) report col 1 of A < col 1 of B.
What about custom block predicate

usaed this way
![]()
Yes, I like @dardoro solution.
Also, we can do the same using only booleans logic. For example:

Joan
From someone who worked for 5 years in the field of data-analysis, let me show you how everybody does this in practice rather than in theory:
if you use this approach don't forget to make sure that all columns have the same characters-length before applying the sort, and - if you have decimal points - that they're all normalized.
Hey @jens, this is pretty simple and cool!
Only note that "this normalization" could be hard. For example, with negative numbers. And also, if original data can't be permanently modified (normalized), sorting reporter will be more complex than sorting by items.
Joan
Hi Joan, yes, that's right. My professional experience with data crunching at MioSoft has been to do large-scale string transformations on giant data sets a lot, so writing these kinds of "normalizations" has been the most work, and the actual gaining of insights used to be the easy part 
here's how one might do a simple reporter that fills up a field with an arbitrary prefix in Snap:
in practice with real customer data we never had negative numbers, they don't occur in contracts or account balances, instead you usually have two separate fields for debit and credit.
It works with extra, not so obvious, assumption about input data and usually requires kind of normalization, as shown. Contrary to numbers, text must normalized by suffixes or join with special crafted separators to work for edge cases.
E.g for "Smith Jr","Alan";
"Smith", "Wiliam"
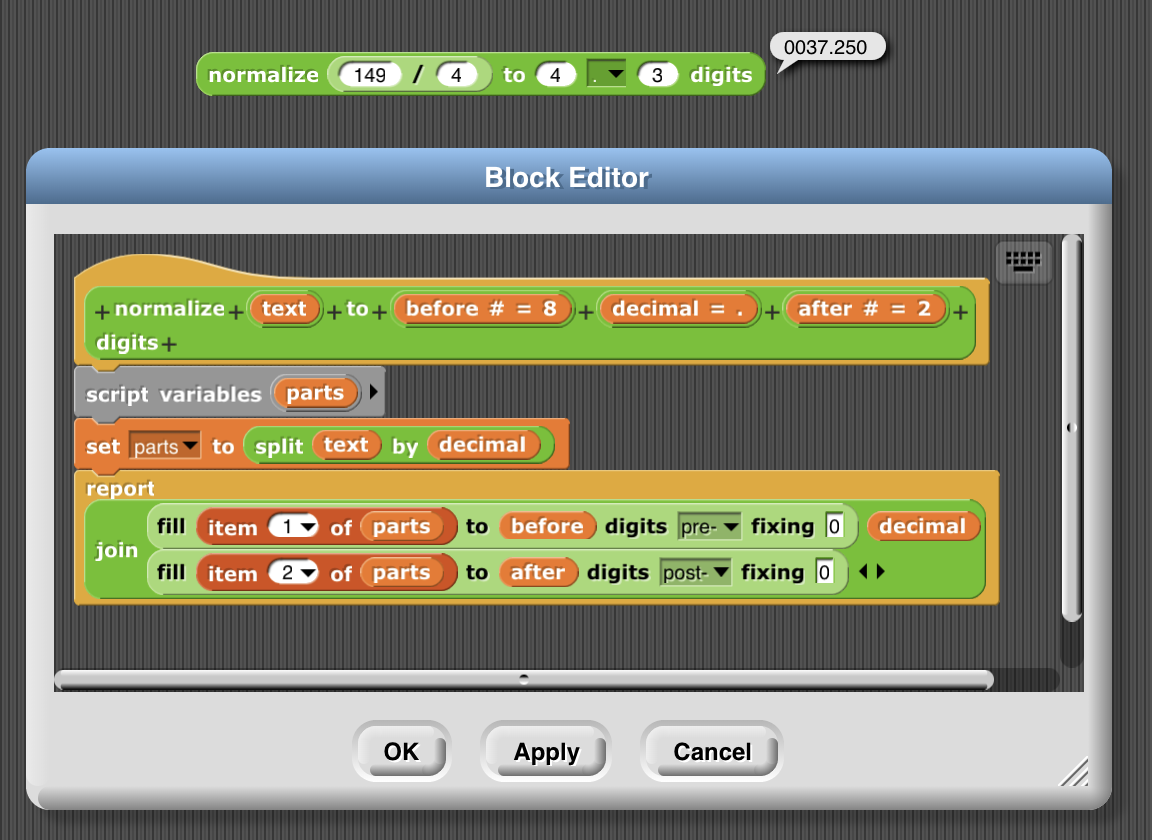
that's right. But in fact, this kind of string-transformation can be fun! For numbers you can add another input to the function above specifying whether to pre- or suf-fix the filling:
then you can make your own normalization function for decimals:
(here's the project with the blocks: https://snap.berkeley.edu/project?user=jens&project=multi-column%20sort)
Jens, I see it is possible to drag a list into a no-slots JOIN block.

I like it.
you can do this with all variadic input slots!
Except for the one in the list reporter, of course.